Today we release LibreOffice 4.4.0, packed with a load of new features for people to enjoy - you can read and enjoy all the great news about the user visible features from so many great hackers, but there are, as always, many contributors whose work is primarily behind the scenes in places that are not so easy to see. That work is, of course, still vitally important to the project. It can be hard to extract those from the over eleven thousand commits since LibreOffice 4.3 was branched, so let me expand:
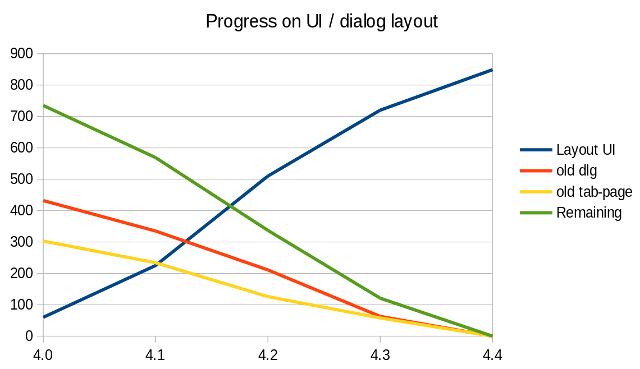
Complete User Interface Dialog / Layout
The UI migration to a much improved, Glade compatible XML
representation of VCL dialogs, complete with automatic layout is now
almost complete (after thinking we'd done them all - Caolan
discovered a lot of docking windows that need further work but these
are now also migrated, all but two). Also a lot of work was put into
cleaning up and tweaking the look / arrangement of dialogs. Many thanks to
Caolán McNamara (Red Hat) - for his incredible work & leadership
here, and to Adolfo Jayme Barrientos, Palenik Mihály (GSoC 2014),
Olivier Hallot (EDX), Szymon Kłos (GSoc 2014), Rachit Gupta (GSoC 2014),
Tor Lillqvist (Collabora), Jan Holesovsky (Collabora), Maxim Monastirsky,
Efe Gürkan YALAMAN, Yousuf Philips and
many others. Thanks also to our translators who hopefully will
have much less string churn to suffer now. As a side-note the
resource-compiler in rsc/ has gone on a nice diet.
Initial OpenGL rendering backend
The switch to move VCL to use OpenGL for rendering is one of those things that ideally should be entirely under-the-hood, but ends up having small but important visual impact. All the work here was done by Collabora engineers, with a beefy re-factor and the initial OpenGLContext management by Markus Mohrhard, much of the rendering implemented by Louis-Francis Ratté-Boulianne with anti-aliasing, and image scaling work from Lubos Lunak, various Windows fixes and porting work from Jan Holesovsky and some bits from Chris Sherlock. During the work we also implemented a half-way decent and increasingly complete VCL demo application exercising rendering. A rational for the work with some pictures is available.
By moving to a pure OpenGL rendering model, we can accelerate those operations that badly need to taking advantage of the power and parallelism of the huge APU die-area given over to modern GPUs. Being able to interact much more directly with the underlying graphics hardware helps us to both render our image previews at high quality, and not to sacrifice scroll / zoom performance: having our cake and eating it too. We've also used some of that power to not only significantly accelerate our image rendering, but also improve its quality too from before:


There is a fair bit more work to get OpenGL into a suitable
state including several odd Windows / lifecycle bugs; it is necessary
to export SAL_FORCEGL=1 to override the black-listing, but
we hope to nail these in the 4.4.x cycle. Several ongoing and intersecting
features such as the true Idle handler work from Munich's Jennifer
Liebel and Tobias Madl as well as more future / pending work in-progress
from Munich's Michael Jaumann (working on OpenGL canvas) and
Stefan Weiberg (on OpenGL Transitions) are due in 4.5, both
mentored by Thorsten Behrens (SUSE).
Mobile Viewer / LibreOfficeKit
The recently announced Android Viewer (Beta) has a number of invisible pieces included there. Particularly the improvements to LibreOfficeKit: an easy way to re-use the rendering and file-format goodness from LibreOffice from Andrzej Hunt and Kohei Yoshida (Collabora) to get Impress and Calc rendering to tiles at least to a Beta level. You can read more about the just started editing work done for TDF there too. LibreOfficeKit has also become more powerful at extracting key document meta-data from yet more of the host of file formats that LibreOffice supports - important for indexing un-structured data.
Build / platform improvements
30% faster Windows builds
With the new build system functionally completed, we've looked at the most significant problem with it: rather slow build times on Windows. An investigation and some benchmarking revealed that the usage of Cygwin make was the main cause of the slowness, and hence Michael Stahl (Red Hat) made it possible to build LO 4.4 with a Win32 native build of GNU make, cutting from-scratch build time by almost a third over stock Cygwin make, and speeding up incremental rebuilds even more.
Win64 porting action
Another major improvement is from David Ostrovsky (CIB), which is to do some significant work towards completing the native Win64 port. This we expect will ship in LibreOffice 4.5, but should significantly help eg. Java users and those with very large spreadsheets. See the Windows 64bit wiki page for more detail, thanks also to Mark Williams for some tricky UNO bridge fixing work, and to Tor Lillqvist (Collabora) who laid a lot of the initial ground-work here.
Code quality work
There has been a lot of work on code quality and improving the
maintainability and cleanliness of the code. Another 59 or so commits
to fix cppcheck errors are thanks to Thomas Arnhold,
Julien Nabet and Simon Danner, along with the daily commits to
build without any compile warnings -Werror -Wall -Wextra
on many platforms with thanks primarily to Tor Lillqvist (Collabora),
Caolán McNamara (Red Hat), and Thomas Arnhold.
Awesome Coverity
We have been chewing through the huge amount of analysis from the Coverity Scan, well - in particular Caolán McNamara (Red Hat) has done an awesome job here; his blog on that is typically modest.
We now have a defect density that bumps along close to 0.00, though as Coverity introduces new checks, and new code gets committed that goes up and down a little; currently 0.02 so - 2 static checking warnings per 100,000 lines. That compares extremely well with the average Open Source project which has 65 warnings per 100,000 lines.
Grokking commits with coverity in them we have 1530 fixes since LibreOffice 4.3 with the top three contributors after Caolan (1378 commits) being: Norbert Thiebaud, David Tardon (Red Hat), Miklos Vajna (Collabora).
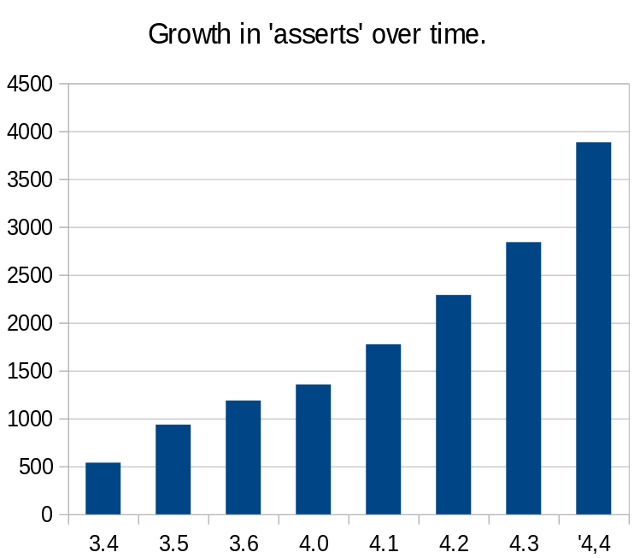
Increasing use of asserts
In the 3.5 release we switched away from custom macros to use normal 'assert' calls to sanity check various invariants; we're doing more sanity checking left and right these days:
Import and now export testing
Markus Mohrhard (Collabora)'s great import/export crash testing has been further expanded to cover 76,000+ problem/bug documents up from 55k last release, with a selection of odd images now also included. Another major win here was the provision by TDF (thanks to our donors) of a beefy new 64 core box to run the load/save/validate tests on. This, combined with some re-working and better parallelism of the python scripts driving that, has speeded up our test runs from five days to under one - allowing rapid diagnosis of new regressions in a much smaller range. We've also been able to do some Addresss Sanitizer runs of the document set which has resulted in a number of fixes, thanks too to Caolán McNamara (Red Hat) for some great work there.
Clang plugins / checkers
We have continued to add to our clang compiler plugins; a quick git grep
for 'Registration' in compilerplugins shows that we've gone from 27
to 38 plugins in the last six months. These check all manner of nasty gotchas that
people can fall into in our code. Some of these plugins are used manually but many
are run by a tinderbox and some users to catch badness quickly. Thanks to:
Stephan Bergmann (Red Hat) and Noel Grandin (Peralex) for their hard work on these
checkers this cycle.
The plugins do all sorts of things, for example Bjoern Michaelsen (Canonical) wrote a plugin that detects deeply-nested conditionals such as these monsters. These are hard to read and a severe pain to debug through. Some of the worst offenders in sw/ have been rewritten and the plugin can easily be applied elsewhere in the codebase.
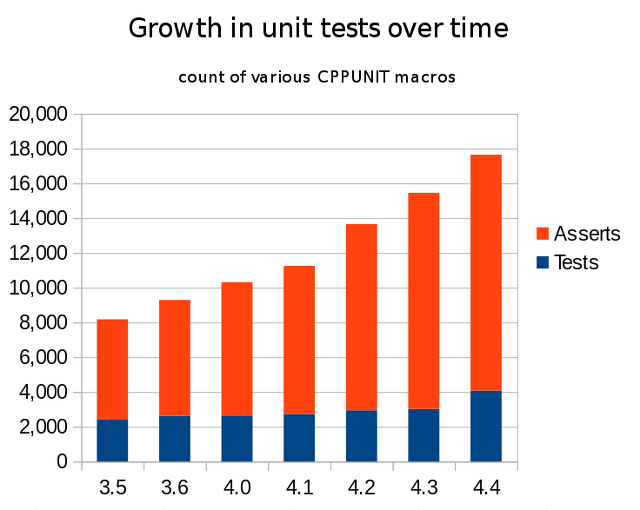
Unit testing
We also built and executed more unit tests with LibreOffice 4.3 to avoid regressions as we change the code. Grepping for the relevant TEST and ASSERT macros we continue to grow the number of unit tests:
qa/
directories: Miklos Vajna (Collabora), Caolán McNamara (Red Hat),
Kohei Yoshida (Collabora), Michael Stahl (Red Hat), Stephan Bergmann (Red Hat),
Zolnai Tamás (Collabora), David Tardon (Red Hat), Noel Grandin (Peralex),
Matúš Kukan (Collabora), Luboš Luňák (Collabora), Markus Mohrhard (Collabora),
Tor Lillqvist (Collabora), Thomas Arnhold, Andrzej Hunt (Collabora),
Eike Rathke (Red Hat), Jan Holesovsky (Collabora)
QA / bugzilla
Over the last six months the QA team has grown in size and effectiveness, doing some amazing work to bring our un-triaged bug count right down from one thousand (which we thought was good) to just over three hundred bugs. It's particularly knotty triaging some of those last bugs - with rather deeply technical, or super-hard-to-reproduce combinations lurking at the bottom: some excellent work there. It is rather hard to extract credits for confirming bugs, but the respective hero list overlaps with the non-developer / top closers listed below.
One metric we watch in the ESC call is who is in the top ten in the freedesktop Weekly bug summary. Here is a list of the people who have appeared more than five times in the weekly list of top bug closers in order of frequency of appearance: Caolán McNamara (Red Hat), Adolfo Jayme, tommy27, Julien Nabet, Jean-Baptiste Faure, Jay Philips, Urmas, Maxim Monastirsky, Beluga, raal, Michael Stahl (Red Hat), Joel Madero, ign_christian, Cor Nouws, V Stuart Foote, Eike Rathke (Red Hat), Robinson Tryon (TDF), Miklos Vajna (Collabora), Matthew Francis, foss, Sophie (TDF), Samuel Mehrbrodt, Markus Mohrhard (Collabora). And thanks to the many others that helped to close so many bugs for this release.
Bjoern Michaelsen (Canonical) also wrote up a new year QA update which is well worth reading.
Another win that should help us tweak our bugzilla to make it more user friendly and better structured is the migration from FreeDesktop infrastructure to TDF, with thanks to FreeDesktop for taking our large bugzilla load for all these years. This was completed recently - so now we file bugs at http://bugs.documentfoundation.org/. Thanks to Robinson 'colonelqubit' Tryon (TDF), and Tollef Fog Heen as well as our sysadmin team for that work. As is perhaps obvious, Robinson is working for TDF (funded by our generous donors) half-time to help improve our QA situation.
Code cleanup
Code that is dirty should be cleaned up - so we did a lot of that.
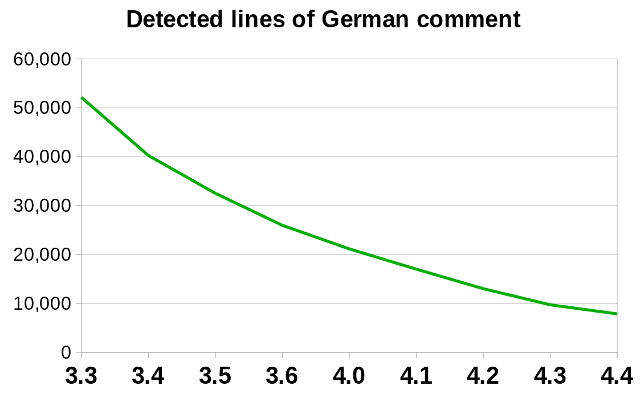
Ongoing German Comment redux
We continued to make progress, but sadly only a small amount of it
on translating our last lingering German comments across the codebase into
good, crisp technical English. This is a great way to get involved in
LibreOffice development. Many thanks to:
Philipp Weissenbacher, Christian M. Heller, Jennifer Liebel (Munich),
Chris Sherlock (Collabora), Michael Jaumann (Munich), Luc Castermans,
Jeroen Nijhof, Florian Reisinger and a number of others with just one
commit. Further reductions in the number of false positives from
bin/find-german-comments suggest that there are only ten
top-level modules left containing German, nine of them worth translating:
i18npool, include, reportdesign, sc, scaddins, sfx2, stoc, svx, sw
One particularly encouraging contributor to our German Comment translation efforts was Lennart Poettering who it seems has an amusing plan afoot.
Upgrading to (some) C++11 subset
As time advances, C++ improves, with the upgrade of Visual Studio we've been able to move to a subset of C++11 (as supported by VS 2012) as a new compiler base-line. We also removed several optimization disabling workarounds for bugs in old GCC versions that don't do C++11 anyway, and hence both GCC and MSVC can now build all of LO with optimization. Thanks to Stephan Bergmann (Red Hat) for researching and driving this work.
OOXML Tokenizer cleanup
This cleanup builds on work by Miklos Vajna (Collabora) in the last release. A big chunk of our OOXML tokenizer was generated code, which is reasonable but it was generated using XSLT (which is trending below cobol). This was re-written from 4200 lines of XLST into 1300 lines of python - to produce the same output with a large increase in hack-ability. Then some optimization was done by Jan Holesovsky (Collabora for CloudOn), to reduce inefficiency in the generated output saving 2.2Mb from the 8Mb (stripped) writerfilter DSO. Great to see this sort of code cleanup, source size shrink and binary shrink at the same time. You can read more about it in Miklos' blog.
std:: containers
A systematic set of improvements to our usage of the std:: containers has
been going on through the code. Things like avoiding inheritance from std::vector, changing std::deque to std::vector and starting
to use the newer C++ constructs for iteration like for (auto& it : aTheContainer) { ... }. There are many people to credit here, thanks to
Stephan Bergmann (Red Hat), Takeshi Abe, Tor Lillqvist (Collabora),
Caolán McNamara (Red Hat), Michaël Lefèvre, and many others.
Performance improvements
Performance is one of those very hard to see things, that is nevertheless viscerally felt: "why am I still waiting ?". There are a number of rather encouraging performance improvements by different people in LibreOffice 4.4 that are worth noticing.
Autocorrect performance
For reasons that elude me, some people like to have huge auto-correct lists. These are stored as zipped XML. Daniel Sikeler (Munich) put some lovely improvements into the loading of these. In particular he discovered that we were re-parsing our BlockList.xml a large number of times, fixing this made a big difference. Combining that with switching to use the threaded & improved FastParser - yielded a further win. The auto-correct list is loaded after the 1st key-press, so getting this from 4.3 seconds down to 1.5 seconds (for huge correction lists) is a big win.
Image management
While profiling saving in various file formats, it was discovered that we frequently swap in (ie. re-load, and de-compress) images - this of course takes significant CPU time, particularly since we then immediately continue to preserve the (original) data in the file. In some cases this was taking a large proportion of save time for large image-filled presentations eg. Thanks to Tamaz Zolnai (Collabora) for cleaning up and fixing this, as well as hunting perennial image loss issues.
Fast Serializer
As a general rule any class named 'Fast' in the inherited OpenOffice code is a horrible mis-nomer. Many thanks to Matus Kukan (Collabora) for fixing this. We discovered that 25% of save time of large XLSX sheets was consumed in the Fast Serializer, which did a staggering 9.9 million system-calls, each writing some tiny fragment of an XML attribute eg. separate writes for opening elements, element names, attribute names namespaces etc. Matus reduced this to 76k calls to do the same thing, a 99% decrease. Quite apart from the system-call overhead we reduced cachegrind CPU pcycles for 'SaveXML' from over 12bn to under 3bn for a simple sample.
Bundle libjpeg-turbo
It has been known for many years that JPEG-turbo provides superior de-compression performance - "In the most general terms, libjpeg-turbo is 2.1 - 5.3x as fast as libjpeg v6b and 2.0 - 5.8x as fast as libjpeg v8d.". Naturally Linux vendors use the system packaged libjpeg, but when we distribute on Windows - we now bundle a 2x speed-up in the form of libjpeg-turbo - thanks to Matúš Kukan (Collabora) with some cleanups from Stephan Bergmann (Red Hat). Volunteers to make jpeg-turbo integrate nicely on Mac appreciated.
Mail merge performance
Mail-merge works by building a huge document containing the result of all the mails to be printed / merged into a single file. The wisdom of this is highly debatable, but nevertheless thanks to Lubos Lunak & Miklos Vajna (both Collabora for Munich) who put some significant effort in to very substantially accelerate large document merge, in some cases by several orders of magnitude. Sadly OpenOffice.org took a major regression here in version 3.3, and that is now comprehensively fixed. This turns a 2000 record mail-merge from a matter of hours down to a few minutes.
Calc Performance
There were a number of rather pleasant performance wins in this release of LibreOffice, which cumulatively have rather a helpful effect.
Range dependency re-work
For previous LibreOffice releases Kohei Yoshida (Collabora) spent a big block of time unifying runs of similar formulae into FormulaGroups - that fill down a large span of a column - since this is a common case for large data sets. This allowed a large memory reduction, and lots of great data sharing. However dependency management was de-coupled from this and was still performed per-cell. That is particularly expensive if you consider a range reference that is common for the whole formula group: resulting in lots of setup, and tear-down cost: essentially to notify the entire formula group. In 4.4 calc adds a listener type that is tailored for these formulae groups - potentially turning tens of thousands of complex data structure entries into a single entry. This saves a large chunk of memory, and a lot of CPU time walking lists, it also saves a ton of time when broadcasting the changes. There is plenty more work to be done to extend this, and ideally in future we should use the same approach for single-cell references as well. Thanks too to Eike Rathke (Red Hat) and Markus Mohrhard (Collabora) for some associated fixes.
Script type optimizations
For various reasons, detecting the script-type of a cell is an expensive operation; is it some asian text, complex text or simple - which affects the font, sizing & various metrics. Kohei Yoshida (Collabora) discovered that in several common operations - copying/pasting large chunks of data - that this work was being needlessly re-done and removed this cost. Similarly, for simple data types with standard formatting on eg. a large span of doubles, it was possible to significantly simplify the calculation of script types.
Chart deferred re-rendering
Another area that (still) causes some grief is that whenever a data range changes which a chart depends on, the entire chart is re-generated. That involves tearing down a lot of drawing shapes and re-creating them, which in the case of text is particularly expensive. Kohei Yoshida (Collabora) implemented a great optimization to defer this work until the chart is visible. This should have a pleasant effect on editing time for large data sets which are charted on many other sheets, and also for macros operating on many charts.
Getting involved
I hope you get the idea that more developers continue to find a home at LibreOffice and work together to complete some rather significant work both under the hood, and also on the surface. If you want to get involved there are plenty of great people to meet and work alongside. As you can see individuals make a huge impact to the diversity of LibreOffice (the colour legends on the right should be read left to right, top to bottom, which maps to top down in the chart):
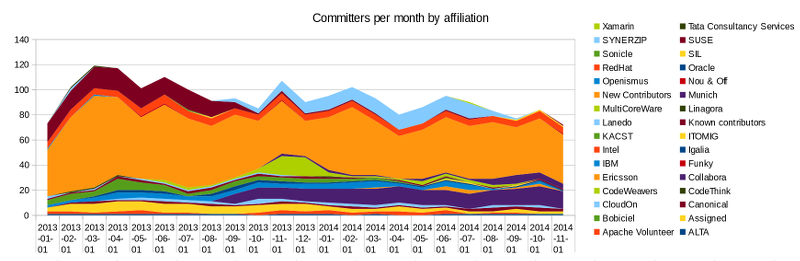
And also in terms of diversity of code commits, we love to see the unaffiliated volunteers contribution by volume, though clearly the volume and balance changes with the season, release cycle, and volunteers vacation / business plans:
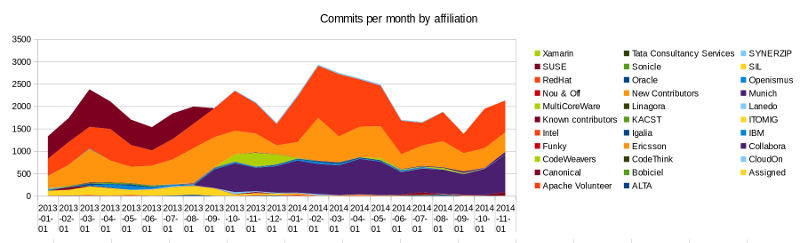
Naturally we maintain a list of small, bite-sized tasks which you can use to get involved at our Easy Hacks page, with simple build / setup instructions. It is extremely easy to build LibreOffice, each easy-hack should have code pointers and be a nicely self contained task that is easy to solve. In addition some of them are really nice-to-have features or performance improvements. Please do consider getting stuck in with something.
Another thing that really helps is running pre-release builds and reporting bugs just grab and install a pre-release and you're ready to contribute alongside the rest of the development team.
Conclusion
LibreOffice 4.4 is the next in a series of releases that incrementally improve not only the features, but also the foundation of the Free Software office suite. It is of course not perfect yet, this is just the first in a long series of monthly 4.4.x releases which will bring a stream of bug fixes and quality improvements over the next months as we start working in parallel on LibreOffice 4.5.
I hope you enjoy LibreOffice 4.4.0, thanks for reading, don't forget to checkout the user visible feature page and thank you for supporting LibreOffice.
Raw data for many of the above graphs is available.
A great French translation of this is kindly made available at linuxfr.

{kind=link}